Pt1. Capturando feed de dados em tempo real com Python
O objetivo deste projeto é desenvolver uma aplicação para capturar dados em tempo real e em alta velocidade do order book de uma exchange de criptoativos. Utilizando as capacidades de programação assíncrona do Python 3.9 e serviços da AWS, a aplicação será capaz de armazenar os dados em uma tabela do DyanamoDB. Esses dados serão disponibilizados em uma API REST.
Neste primeiro post escreverei sobre o processo de captura dos dados. Nos posts seguintes, falarei sobre a criação da API utilizando AWS Lambda e DynamoDB.
Algumas definições
O principal modo do investidor interagir com o mercado de criptoativos atualmente é através de exchanges como a Binance, Ftx, Coinbase, Bitfinex, Bitstamp e muitas outras. Pelo app da exchange o trader pode colocar instruções [lerry harris] indicando o tipo de ativo, o par de moeda, a quantidade e qual lado da negociação (compra ou venda) deseja tomar. Essas instruções são as ordens (orders). O investidor pode colocar, por exemplo, uma ordem de compra de 10 unidades no par btcusd para quando o preço chegar a U$40000. Esse tipo de negociação é chamada de limit order e só será executada se o preço de venda chegar nesse nível e se houver liquidez (um número suficiente de vendedores) para preencher a ordem. Quando o investidor deseja execução imediata, faz um market order: define a quantidade e o par, o preço da execução será o melhor preço de venda disponível no momento até a ordem ser totalmente preenchida.
Cada ordem colocada no mercado é a expressão das crenças de um investidor sobre aquele determinado ativo, no curto ou longo prazo. Se ele acha que o preço sobe, então coloca uma ordem de compra; se acha que o preço cai, vende. Essas ordens, enquanto estão ativas, compõem o order book da exchange.
Boa parte das exchanges fornecem api’s do feed de alguns dados em tempo quasi real. Porém, não são todas que fornecem os dados do order book na menor granularidade possível, ordem a ordem. Esse post diz um pouco mais sobre os níveis do order book: Kaiko
A Bitstamp é uma das poucas que disponibiliza os dados detalhados. Podemos enxergar cada ordem de bid/ask adicionada, atualizada ou deletada do livro. Ter acesso à esses dados possibilita analizar e testar hipoteses sobre a formação dos preços, buscar oportunidades de arbitragem e desenvolver estratégias de HST (high speed trading). O primeiro passo, no entanto, é capturar esses dados e inseri-los em um banco de dados.
Capturando os dados
As API’s em tempo real geralmente são disponibilizadas em Websocket. Websocket é um protocolo criado sobre a camada TCP e que se inicia através do protocolo HTTP tornando possível uma comunicação ponto a ponto em ambos os sentidos cliente-servidor. A conexão é iniciada com uma request disparada para o endereço do host com o HTTP verb GET. Em seguida um cabeçalho de upgrade é enviado do cliente para o servidor, acontece o handshake e a conexão se firma (linhas 6 a 8 da imagem a seguir).
Com a conexão estabelecida, agora existe um canal entre o cliente e o servidor na mesma porta utilizada pelo protocolo HTTP (80) ou na porta 443. É através deste canal que acontece a trasmissão de mensagens.
No caso da aplicação explicada neste post, a primeira mensagem é enviada para o host e contém um item json com o pedido de inscrição a um canal (linha 22).
O servidor devolve uma resposta com o status do pedido (linha 25) e partindo daí se incia a transmissão de dados.
Os detalhes do websocket são explicados aqui na documentação tecnica
Os eventos no order book são expressos em milisegundos e chegam pelo feed com o atraso da latência (~100ms no caso do teste) e mais algum overhead do código (linha 34 em diante).
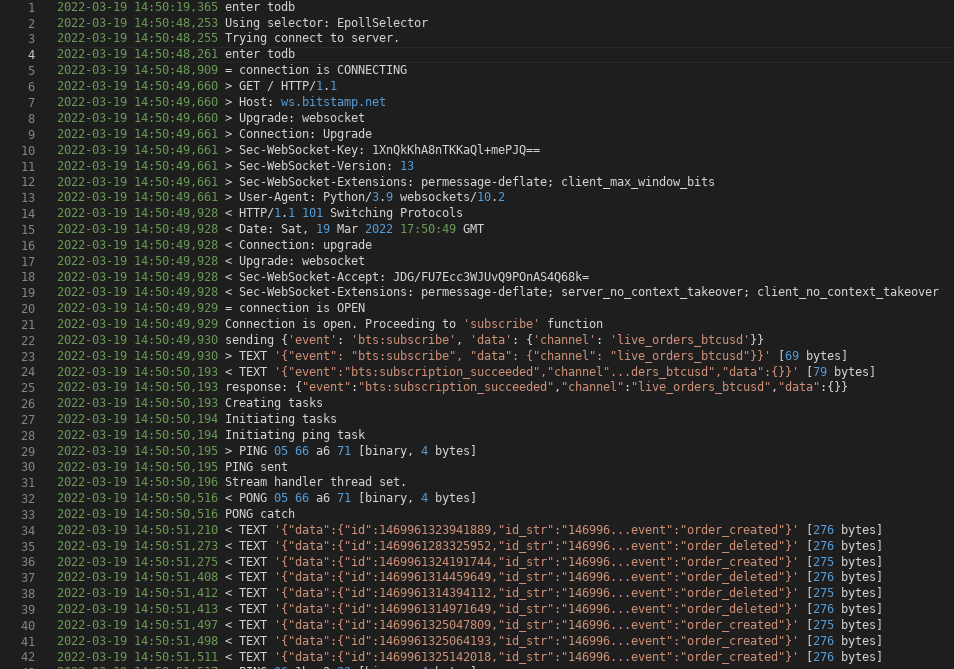 Trecho do log gerado ao iniciar a aplicação
Trecho do log gerado ao iniciar a aplicação
Para ter uma boa integridade na recepção e no armazenamento dos dados, de início eu imaginei duas condições que o código deveria atender: primeiro a recuperação após uma perda de conexão ou exception deveria ser rápida. Segundo: a recepção dos dados não poderia ser limitada por outras funções do programa, como por exemplo, ser suspensa porque o event loop principal está ocupado com gravação no banco de dados.
Para o primeiro problema eu esperava que os próprios timeouts da biblioteca Websockets dessem conta de emergir um erro, já que existe o parâmetro keep_alive na criação da conexão.
Para o segundo, a minha ideia original era criar uma thread e uma conexão separada para cada canal.
Python e asyncio
O código do projeto é baseado na biblioteca Websockets e na asyncio. A biblioteca asyncio foi introduzida no Python 3.4 e bastante aprimorada até o Python 3.9. Considerando que o Python é uma linguagem single thread, a asyncio implementa uma api que possibilita atribuir operações de I/O (entrada e saida de dados) a corrotinas e tasks e essas podem ser executadas em concorrência. Isso é possível porque o GIL (Global Interpreter Lock) não bloqueia concorrência em operações io-bound. Ja no caso de operações que são dependentes do CPU (cpu-bound), o único modo de atingir concorrência é criando multiprocessos.
Existe uma série de cuidados que devem ser tomados ao lidar com concorrência em Python. Para aplicações críticas e que necessitam de baixa latência o ideal é utilizar linguagens que não possuem tantas limitações nesse sentido (C, C++, Java, Erlang, Elixir…), caso contrário é necessário ter sempre em mente que existe um overhead ao utilizar multiplas threads e processos e ainda compartilhar variáveis entre eles.
Aqui isso não faz tanta diferença. A preocupação principal é garantir que não haja bloqueio do loop que recebe as mensagens e para isso a asyncio é suficiente. E olhando esse gráfico do livro High Performance Python, podemos ter uma noção que o poder de processamento está bem acima da velocidade de i/o:
“For example, in the time it takes to write to a network socket, an operation that typically takes about 1 millisecond, we could have completed 2,400,000 instructions on a 2.4 GHz computer. Worst of all, our program is halted for much of this 1 millisecond of time—our execution is paused, and then we wait for a signal that the write opera‐ tion has completed. This time spent in a paused state is called I/O wait.”
 Outro livro que me ajudou muito nesse processo de trabalhar com a asyncio foi o Python Concurrency with Asyncio. Esse livro cobre com detalhes as possibilidades que temos hoje em paralelismo, concorrência e multitarefas no Python com uma riqueza grande de exemplos que permitem entender bem como a biblioteca trabalha.
Outro livro que me ajudou muito nesse processo de trabalhar com a asyncio foi o Python Concurrency with Asyncio. Esse livro cobre com detalhes as possibilidades que temos hoje em paralelismo, concorrência e multitarefas no Python com uma riqueza grande de exemplos que permitem entender bem como a biblioteca trabalha.
O código
O código completo está aqui. Neste tópico irei comentá-lo por partes.
Utilizando o sdk da AWS para python, a biblioteca boto3, eu defini o caminho para a tabela do DynamoDB nas linhas 3 e 4 do gist abaixo. Em seguida vem as configuraçeõs de logging. Aqui é necessário tomar cuidado, quando em modo DEBUG o arquivo de log chega aos GB em poucos minutos. É preferível utilizar o modo INFO.
O função to_db() deve ser implementada para fazer a inserção das mensagens no database. Essa função é executada em um processo diferente (linhas 16 e 17). Para comunicar o programa principal com a função do banco de dados eu tinha duas opções: usar um Pipe() e conectar a função handler com a to_db(), ou utilizar esse Manager, que permite compartilhar um espaço de memória entre dois ou mais processos diferentes e usar uma Queue(), que era a opção mais adequada já que as mensagens poderiam ser empilhadas na queue enquanto as operações do banco de dados eram concluidas.
É necessário informar qual o endereço do host e adicionar a uma lista as mensagens de subscribe no formato JSON ao instanciar a classe GetStream. Essas informações estão na docomentação de cada API. Há casos onde a inscrição é feita diretamente pela url do websocket. Neste caso a lista de canais pode ficar vazia. Aqui no exemplo a inscrição será feita em 4 canais. O loop principal é invocado com o método initiate()
A construção e inicialização do objeto é feita a seguir. É interessante notar que a exception do tipo KeyboardInterrupt não é capturada em nenhuma outra função, apenas na mais “externa”. Neste caso, a função que cria o event loop.
Esse comportamento é discutido em maiores detalhes nessa issue. Uma das grandes lições aprendidas com a asyncio é que nem sempre o error handling acontece como esperamos. Com alguma pesquisa consegui contornar os problemas e achei posts interessantes sobre o assunto, como esse da Qantlane.
O pedido de conexão é feito em um async for (linha 4) dentro da classe GetStream. Em caso de exception nas corrotinas, o erro será capturado no error handler do método connect_ws e automaticamente irá tentar a reconexão. O método to_thread pertence à biblioteca asyncio. É um wrapper que permite de modo rápido definir que uma corrotina será executada em uma thread separada. O método gather garante que as duas tasks serão executadas ao mesmo tempo. Esse método só retorna quando ambas as tasks são finalizadas (status done). Como são dois loops, isso só acontece em caso de erro.
Para vigiar a conexão, as funções built-in da biblioteca Websockets eram muito lentas. Demoravam de 20 a 30 segundos para levantar um TimeoutError mesmo quando setadas para 1 segundo (é exatamente esse tipo de comportamento imprevisível que é tratado no post da Quantlane linkado acima). Por conta disso eu implementei a get_echo(), que envia uma mensagem Ping e espera uma resposta com timeout ajustável. Se não obtiver resposta, o erro é logado e chega ao loop da conexão onde irá iniciar a tentativa de reconexão. Se receber a resposta do servidor (Pong) a função dorme por um segundo (sem bloquear o loop) e então reinicia.
A stream_handler é executado em uma thread separada. Ela recebe as mensagens do método recv() e empilha na queue - o async for message in ws: é um wrapper ao redor da recv() . Essa queue então alimenta o processo separado to_db() e as mensagens são enviadas para o banco de dados através do método put() da biblioteca boto3.
A própria library Websockets ao receber as mensagens também as coloca em uma queue, lendo o código entendi como funciona em um nível mais baixo da API: cada mensagem que chega é adicionada na fila e fica à espera da chamada do metodo recv. Se acumular mensagens, a fila deixa de ser alimentada (daí a minha preocupação de receber as mensagens em um processo independente) e as primeiras mensagens são mantidas na espera até serem processadas (modelo FIFO).
Eu desisti da ideia inicial de criar uma conexão para cada canal. A ideia não era boa: consome mais recursos da máquna virtual e as exchanges limitam a quantidade de conexões por cliente. Faz sentido, já que cada mensagem tem aproximadamente 200 bytes e é muito mais oneroso para o servidor criar uma nova conexão que adicionar um feed à uma conexão já existente.
Esse código é executado em uma instância EC2 com 1GB de ram e alimenta uma tabela do DynamoDB, escreverei sobre no próximo post. Ainda é necessário executar alguns experimentos de profiling para obter as dimensões reais dos recursos utilizados e dos tempos de execução neste script.